

Daily robotics journey update (part 2)
Replicating the Generative Value Learning Paper
Wendesday, 10th of July
I collected the last episodes this morning and then went through the data to make sure that there are no errors in the data that the model tries to learn on. I then merged the datasets to one using Phospho and am now waiting for the upload to Huggingface to complete.
In the meantime I read the paper Vision Language Models are In-Context Value Learners which the founder from Dyna wrote during his PhD and is building on at the company. The paper proposes a method called Generative Value Learning (GVL), which uses a frozen vision-language model (VLM) to assign progress scores (between 0 and 1) to video frames of a robot performing a task. Unlike naive prompting, which produces uninformative monotonic scores due to temporal biases, GVL shuffles video frames and treats value prediction as a temporal ordering task, forcing the VLM to reason more deeply about task semantics and progress.
These frame-wise scores can then be used for:
- success detection (e.g. to filter out failed trajectories),
- dataset quality estimation,
- and advantage-weighted imitation learning — enabling robots to autonomously learn from their own experience, without requiring external reward labels or human supervision.
This is what it look likes in the Dyna research blogpost:
This is from an experiment I did comparing the Gemini models and GPT:
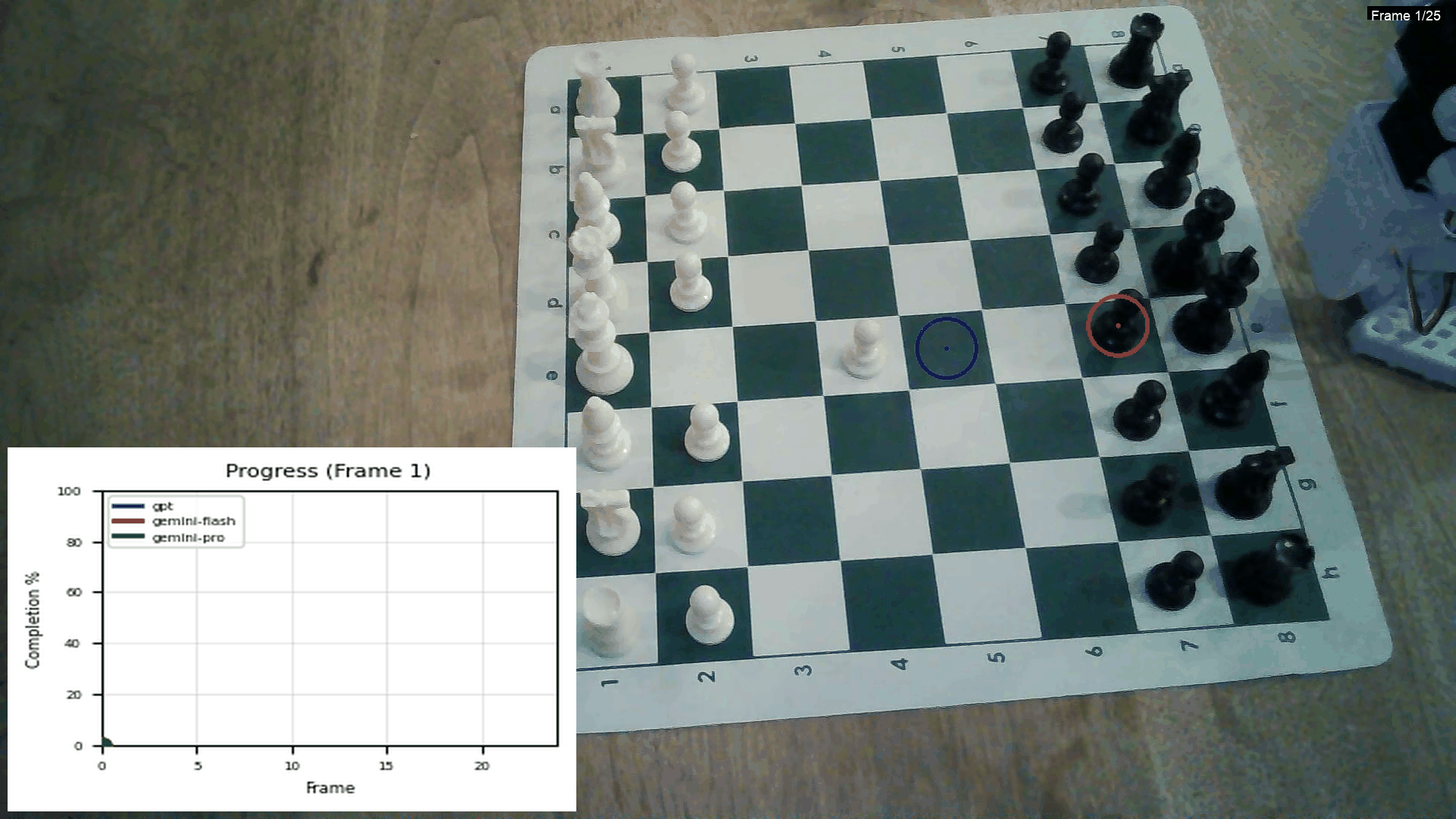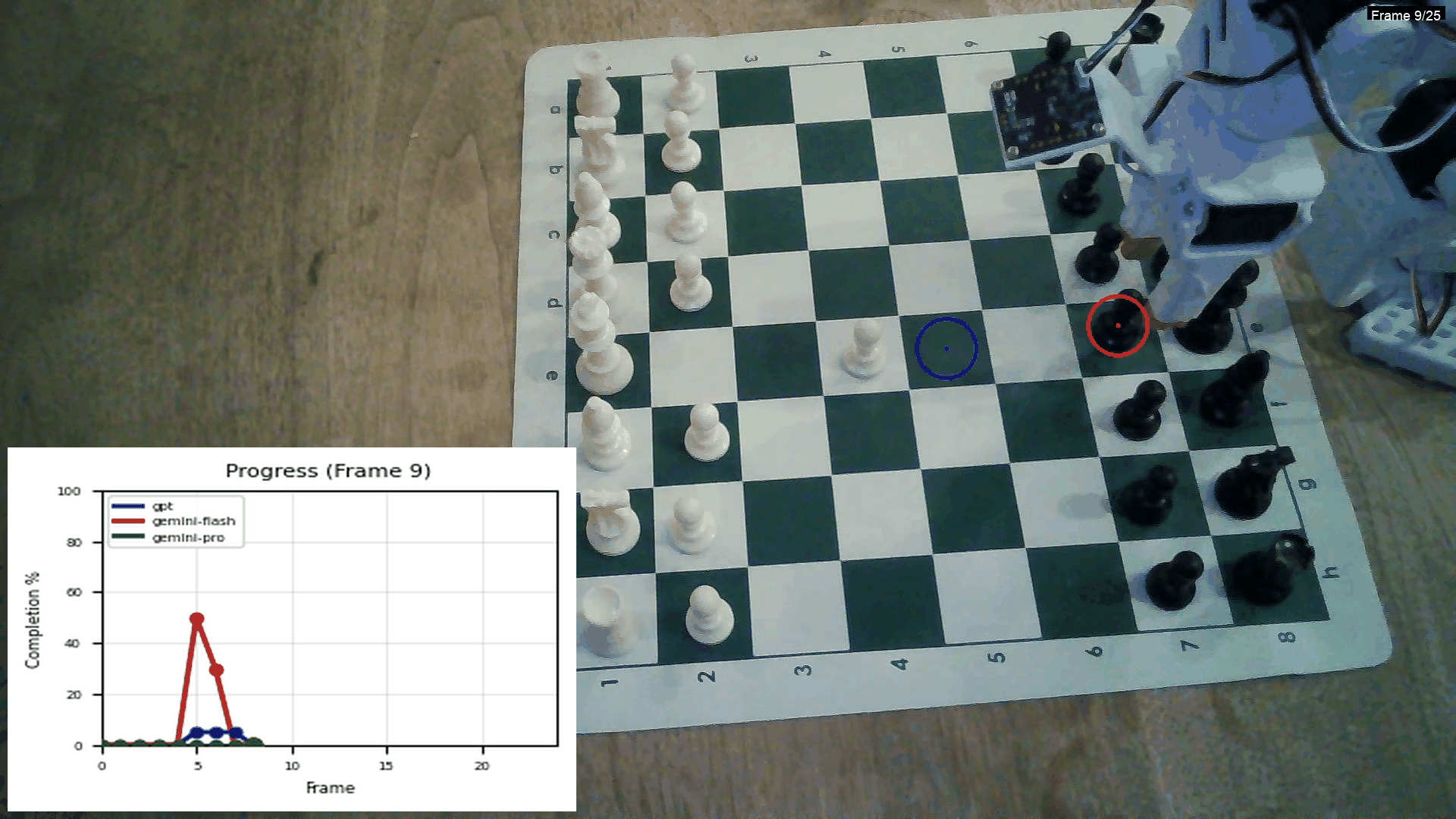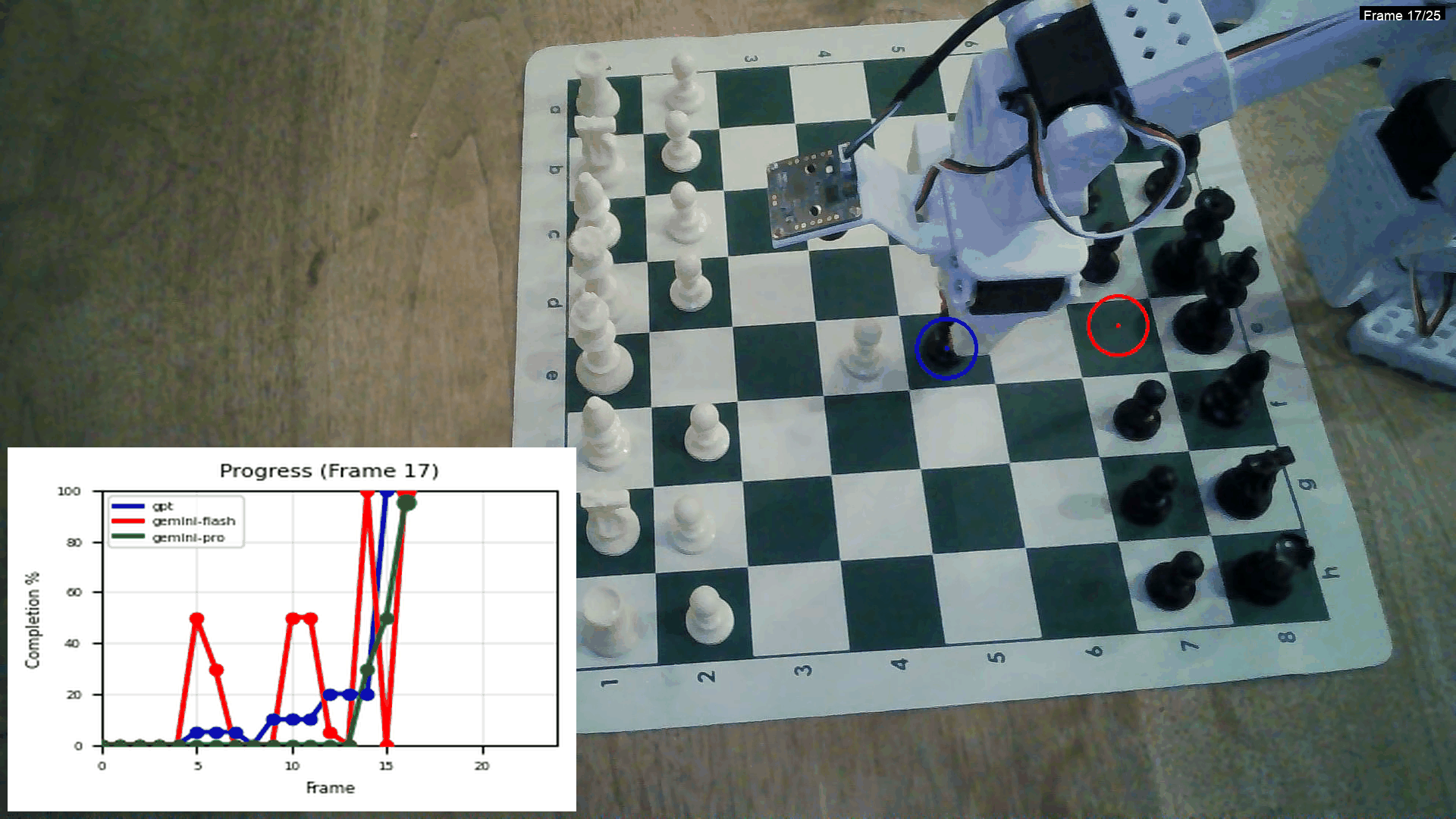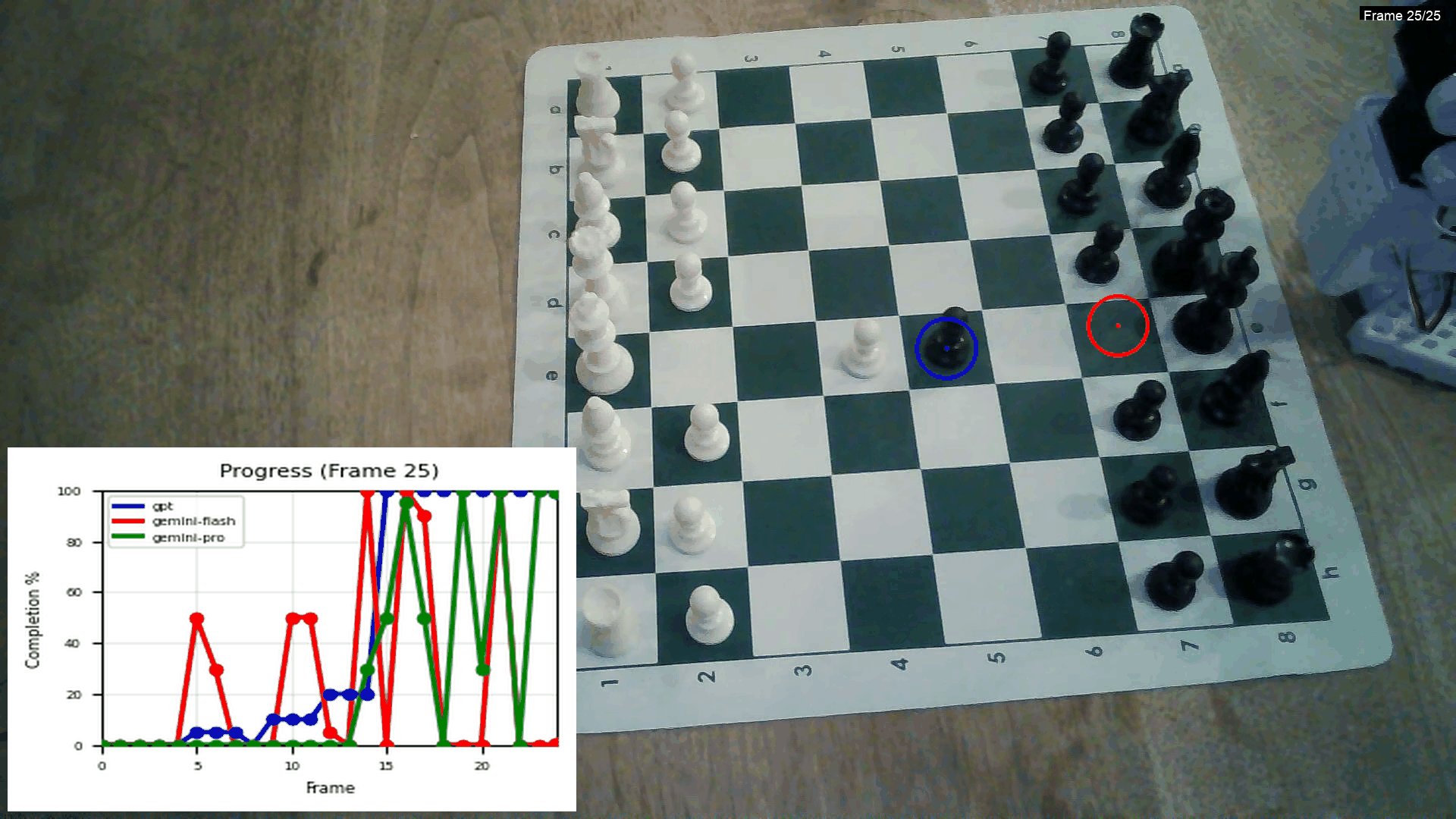
Using GPT for this is really expensive though! Creating 5-10 of these videos costs 2$! One thing that I haven't implemented yet is a in-context example with frames of the task, this might make the lines significantly smoother.
Why am I doing this? While I hope that the model trained on 1500 samples will be significantly better than the model trained on 500, I am certain that it wont't work with >90% success. I've been thinking how I could get there (except collecting more data). Applying this method to data collected by the robot autonomously could be an interesting avenue.
Also, I enjoyed listening to this podcast with the Karol Hausman, CEO of Physical Intelligence, and a staff researcher and highly recommend it.
Collecting 1500 episodes
Monday & Tuesday, 8th/9th of July
I spent the days just collecting data. The changes to the recording script HUGELY improve the time it takes to collect data. What took me 1h before is now 20m of data collection and 40m of processing time where I can do something else which was continuing reading the General Robots Substack which I also highly recommend.
I also had some time to think and summarise a few learnings for myself:
- Don't save on webcam: I bought a 60€ webcam instead of the Logitech C992 which was used in the Aloha paper and was the camera I was originally considering. The cheap camera I bought is very light sensitive and in normal indirect daylight the white pieces and parts of the chess board are overexposed which I imagine doesn't help the learning process.
- Regularly look at your own data and figure out whether its optimal for learning: I noticed the camera on the arm of the robot is not focussed (you can adjust that manually). Maybe it will add a bit to the robustness of my model, but given the same amount of data more blurry parts of it will be detrimental to quality.
- If you build a robot, try to keep lighting as constant as possible: I noticed in this Dyna demo what lengths they were going through to keep the lighting constant, but looking at my data I notice how many variations in brightness my data has, depending on the time of day. I initially underestimated the number of samples I'd need to get a decent version working (I'm not sure whether 1500 episodes will produce an OK model) and thought that it would be cool to have a robust model that can work in many different settings as this would be 'closer to a real-life' setting. True - but also very painful. Again, I underestimated how many samples it would take and I'd be happy to have a model that somewhat reliably works in ONE setting.
Goal Setting for the Week & Augmenting Script for Faster Data Collection
Sunday, 6th of July
My big hypothesis developed from last week is that I most likely need way more data. I want to disprove or confirm this hypothesis as quickly as possible. I planned the week ahead and set three main goals:
- Collect 1,100 episodes of data and retrain the ACT & SmolVLA models
- Annotate 300 images for the chess piece detection model and retrain it
- Connect the chessboard reading code with the model that executes the chess move
Besides that, I want to use the early mornings of the data collection days — while I’m still fresh — to get some reading done.
The biggest bottleneck in data collection last week was post-processing: recording a 15s episode took 30–40s to encode immediately afterward. This slowed down the loop significantly.
I updated the LeRobot code so that image-to-video processing now happens in batch after recording is complete. This change should halve the time per episode — if not more — and make the entire data collection process significantly faster.
I also read this substack on scaling laws for VLAs.
Meeting people for coffee and 4th of July
Friday, 4th of July
I met with friends visiting SF and a guy I know from the robotics hackathon in Paris who's also founding a company now. I also took some time off to celebrate the 4th of July.
Ok, it was time for a shitty day again
Thursday, 3rd of July
Today I kicked off training for an ACT and SmolVLA model. In the early evening, I tried out the first checkpoints and was disappointed. The 20k step checkpoint of the SmolVLA model doesn't work at all, and the 80k ACT model (this was the furthest checkpoint at the time) isn't much better.
SmolVLA model trained for 20k steps at a 8 sample batch size:
ACT model trained for 80k steps at a batch size of 8:
I need to wait for the final results, but I'm not quite sure what’s best to do if the final models aren't better tomorrow. I'm gonna think out loud:
- First, I should do a systematic evaluation of the checkpoints to understand:
- Which of the two models is working better, and is it by a clear margin?
- Does longer training (later checkpoints) lead to better results? → If yes, then train a model beyond 100k steps.
- The 100 samples where I only move the rooks could be confusing to the model. Does a model trained without this data do better?
- I could train another 500 episodes, train on the joint dataset, and see if this improves the model.
- I could do a literature review on how others have trained imitation learning models and see if there are any tricks to get this done.
Ok, I just revisited this video I had seen 1–2 months ago of someone else who built a chess robot. I noticed the description saying it’s trained on 1500 episodes! I currently have 500 — or 400 if you only count episodes from chess games — so maybe I just need to collect more data. The robots in the video have a better setup:
(1) The robots are in a fixed position relative to the chessboard, and
(2) Their camera is pointing at the pieces from below, such that the pieces are in view from the beginning.
Maybe the solution really is just collecting more data.